目录
三、使用 HttpClient 和 HtmlParser 实现简易爬虫
一、前言
网页离线存取
package parser;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.FileWriter;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.MalformedURLException;
import java.net.URL;
/**
* 基本能实现网页抓取,不过要手动输入URL 将整个html内容保存到指定文件
*
* @author chenguoyong
*
*/
public class ScrubSelectedWeb {
private final static String CRLF = System.getProperty("line.separator");
/**
* @param args
*/
public static void main(String[] args) {
try {
URL
InputStream instr = ur.openStream();
String s, str;
BufferedReader in = new BufferedReader(new InputStreamReader(instr));
StringBuffer sb = new StringBuffer();
BufferedWriter out = new BufferedWriter(new FileWriter(
"D:/outPut.txt"));
while ((s = in.readLine()) != null) {
sb.append(s + CRLF);
}
System.out.println(sb);
str = new String(sb);
out.write(str);
out.close();
in.close();
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
基本能实现网页抓取,不过要手动输入URL,此外没有重构。只是一个简单的思路。
二、htmlparser 使用
htmlparser是一个纯的java写的html解析的库,htmlparser不依赖于其它的java库,htmlparser主要用于改造 或提取html。htmlparser能超高速解析html,而且不会出错。毫不夸张地说,htmlparser就是目前最好的html解 析和分析的工具。无论你是想抓取网页数据还是改造html的内容,用了htmlparser绝对会忍不住称赞。由于htmlparser 结构设计精良,所以扩展htmlparser 非常便利。
Htmlparser中文论坛. http://bbs.hexiao.cn/thread.php?fid=6
|
Constructor
Summary |
Parser()
Parser(URLConnection connection)
Construct a parser
using the provided URLConnection.
Method:
static Parser createParser(String html,
String charset)
Creates the parser
on an input string.
void visitAllNodesWith(NodeVisitor visitor)
Apply the given
visitor to the current page.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Constructor
Summary |
|
|
|
|
|
|
|
NodeList extractAllNodesThatMatch(NodeFilter filter)
Filter the list
with the given filter non-recursively.
NodeList extractAllNodesThatMatch(NodeFilter filter,
boolean recursive)
Filter the list
with the given filter.
1. html代码里面所有的链接地址和链接名称
package parser;
import org.htmlparser.Parser;
import org.htmlparser.Node;
import org.htmlparser.NodeFilter;
import org.htmlparser.Parser;
import org.htmlparser.filters.TagNameFilter;
import org.htmlparser.tags.LinkTag;
import org.htmlparser.tags.TableTag;
import org.htmlparser.util.NodeList;
import org.htmlparser.util.ParserException;
import org.htmlparser.visitors.HtmlPage;
/**
* htmlparser取得一段html代码里面所有的链接地址和链接名称
*
* @author chenguoyong
*
*/
public class Testhtmlparser {
/**
* @param args
*/
public static void main(String[] args) {
String htmlcode = "<HTML><HEAD><TITLE>AAA</TITLE></HEAD><BODY>"
+
"<a href='http://topic.csdn.net/u/20080522/14/0ff402ef-c382
+ "<a href='http://topic.csdn.net'>连接2</a></BODY></HTML>";
// 创建Parser对象根据传给字符串和指定的编码
Parser parser = Parser.createParser(htmlcode, "GBK");
// 创建HtmlPage对象HtmlPage(Parser parser)
HtmlPage page = new HtmlPage(parser);
try {
// HtmlPage extends visitor,Apply the given visitor to the current
// page.
parser.visitAllNodesWith(page);
} catch (ParserException e1) {
e1 = null;
}
// 所有的节点
NodeList nodelist = page.getBody();
// 建立一个节点filter用于过滤节点
NodeFilter filter = new TagNameFilter("A");
// 得到所有过滤后,想要的节点
nodelist = nodelist.extractAllNodesThatMatch(filter, true);
for (int i = 0; i < nodelist.size(); i++) {
LinkTag link = (LinkTag) nodelist.elementAt(i);
// 链接地址
System.out.println(link.getAttribute("href") + "\n");
// 链接名称
System.out.println(link.getStringText());
}
}
}
结果如下:
http://topic.csdn.net/u/20080522/14/0ff402ef-c382
连接1
http://topic.csdn.net
连接2
2. 使用HtmlParser抓去网页内容
package parser;
import org.htmlparser.Parser;
import org.htmlparser.beans.StringBean;
import org.htmlparser.filters.NodeClassFilter;
import org.htmlparser.parserapplications.StringExtractor;
import org.htmlparser.tags.BodyTag;
import org.htmlparser.util.NodeList;
import org.htmlparser.util.ParserException;
/**
* 使用HtmlParser抓去网页内容: 要抓去页面的内容最方便的方法就是使用StringBean. 里面有几个控制页面内容的几个参数.
* 在后面的代码中会有说明. Htmlparser包中还有一个示例StringExtractor 里面有个直接得到内容的方法,
* 其中也是使用了StringBean . 另外直接解析Parser的每个标签也可以的.
*
* @author chenguoyong
*
*/
public class GetContent {
public void getContentUsingStringBean(String url) {
StringBean sb = new StringBean();
sb.setLinks(true); // 是否显示web页面的连接(Links)
// 为了取得页面的整洁美观一般设置上面两项为true , 如果要保持页面的原有格式, 如代码页面的空格缩进 可以设置为false
sb.setCollapse(true); // 如果是true的话把一系列空白字符用一个字符替代.
sb.setReplaceNonBreakingSpaces(true);// If true regular space
sb
.setURL("http://www.blogjava.net/51AOP/archive/
System.out.println("The Content is :\n" + sb.getStrings());
}
public void getContentUsingStringExtractor(String url, boolean link) {
// StringExtractor内部机制和上面的一样.做了一下包装
StringExtractor se = new StringExtractor(url);
String text = null;
try {
text = se.extractStrings(link);
System.out.println("The content is :\n" + text);
} catch (ParserException e) {
e.printStackTrace();
}
}
public void getContentUsingParser(String url) {
NodeList nl;
try {
Parser p = new Parser(url);
nl = p.parse(new NodeClassFilter(BodyTag.class));
BodyTag bt = (BodyTag) nl.elementAt(0);
System.out.println(bt.toPlainTextString()); // 保留原来的内容格式. 包含js代码
} catch (ParserException e) {
e.printStackTrace();
}
}
/**
* @param args
*/
public static void main(String[] args) {
String
url = "http://www.blogjava.net/51AOP/archive/
//new GetContent().getContentUsingParser(url);
//--------------------------------------------------
new GetContent().getContentUsingStringBean(url);
}
}
3.将整个html内容保存到指定文件
package parser;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.FileWriter;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.MalformedURLException;
import java.net.URL;
/**
* 基本能实现网页抓取,不过要手动输入URL 将整个html内容保存到指定文件
*
* @author chenguoyong
*
*/
public class ScrubSelectedWeb {
private final static String CRLF = System.getProperty("line.separator");
/**
* @param args
*/
public static void main(String[] args) {
try {
URL
InputStream instr = ur.openStream();
String s, str;
BufferedReader in = new BufferedReader(new InputStreamReader(instr));
StringBuffer sb = new StringBuffer();
BufferedWriter out = new BufferedWriter(new FileWriter(
"D:/outPut.txt"));
while ((s = in.readLine()) != null) {
sb.append(s + CRLF);
}
System.out.println(sb);
str = new String(sb);
out.write(str);
out.close();
in.close();
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
4利用htmlparser提取网页纯文本的例子
package parser;
import org.htmlparser.Node;
import org.htmlparser.NodeFilter;
import org.htmlparser.Parser;
import org.htmlparser.filters.TagNameFilter;
import org.htmlparser.tags.TableTag;
import org.htmlparser.util.NodeList;
/**
* 标题:利用htmlparser提取网页纯文本的例子
*/
public class TestHTMLParser2 {
/**
* 读取目标html内容
*
*/
public static void testHtml() {
try {
String sCurrentLine;
String sTotalString;
sCurrentLine = "";
sTotalString = "";
java.io.InputStream l_urlStream;
java.net.URL l_url = new java.net.URL(
"http://10.249.187.199:8083/injs100/");
java.net.HttpURLConnection l_connection = (java.net.HttpURLConnection) l_url
.openConnection();
l_connection.connect();
l_urlStream = l_connection.getInputStream();
java.io.BufferedReader l_reader = new java.io.BufferedReader(
new java.io.InputStreamReader(l_urlStream));
while ((sCurrentLine = l_reader.readLine()) != null) {
sTotalString += sCurrentLine + "\r\n";
}
String testText = extractText(sTotalString);
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 抽取纯文本信息
* @param inputHtml:html文本
* @return
* @throws Exception
*/
public static String extractText(String inputHtml) throws Exception {
StringBuffer text = new StringBuffer();
Parser parser = Parser.createParser(new String(inputHtml.getBytes(),
"GBK"), "GBK");
// 遍历所有的节点
NodeList nodes = parser.extractAllNodesThatMatch(new NodeFilter() {
public boolean accept(Node node) {
return true;
}
});
System.out.println(nodes.size());
for (int i = 0; i < nodes.size(); i++) {
Node nodet = nodes.elementAt(i);
//字符串的代表性节点:节点的描述
text.append(new String(nodet.toPlainTextString().getBytes("GBK"))
+ "\r\n");
}
return text.toString();
}
/**
* 读取文件的方式/utl 来分析内容. filePath也可以是一个Url.
* @param resource :文件/Url
* @throws Exception
*/
public static void test5(String resource) throws Exception {
Parser myParser = new Parser(resource);
myParser.setEncoding("GBK");
String filterStr = "table";
NodeFilter filter = new TagNameFilter(filterStr);
NodeList nodeList = myParser.extractAllNodesThatMatch(filter);
/*for(int i=0;i<nodeList.size();i++)
{
TableTag tabletag = (TableTag) nodeList.elementAt(i);
//标签名称
System.out.println(tabletag.getTagName());
System.out.println(tabletag.getText());
}*/
TableTag tabletag = (TableTag) nodeList.elementAt(1);
}
public static void main(String[] args) throws Exception {
test5("http://10.249.187.199:8083/injs100/");
//testHtml();
}
}
5.html解析table
package parser;
import org.apache.log4j.Logger;
import org.htmlparser.NodeFilter;
import org.htmlparser.Parser;
import org.htmlparser.filters.NodeClassFilter;
import org.htmlparser.filters.OrFilter;
import org.htmlparser.filters.TagNameFilter;
import org.htmlparser.tags.TableColumn;
import org.htmlparser.tags.TableRow;
import org.htmlparser.tags.TableTag;
import org.htmlparser.util.NodeList;
import org.htmlparser.util.ParserException;
import junit.framework.TestCase;
public class ParserTestCase extends TestCase {
private static final Logger logger = Logger.getLogger(ParserTestCase.class);
public ParserTestCase(String name) {
super(name);
}
/**
* 测试对<table>
* <tr>
* <td></td>
* </tr>
* </table>的解析
*/
public void testTable() {
Parser myParser;
NodeList nodeList = null;
myParser = Parser
.createParser(
"<body> "
+ "<table id=’table1′ >"
+ "<tr id='tro1'><td>1-11</td><td>1-12</td><td>1-13</td></tr>"
+ "<tr id='tro2'><td>1-21</td><td>1-22</td><td>1-23</td></tr>"
+ "<tr id='tro3'><td>1-31</td><td>1-32</td><td>1-33</td></tr></table>"
+ "<table id=’table2′ >"
+ "<tr id='tro4'><td>2-11</td><td>2-12</td><td>2-13</td></tr>"
+ "<tr id='tro5'><td>2-21</td><td>2-22</td><td>2-23</td></tr>"
+ "<tr id='tro6'><td>2-31</td><td>2-32</td><td>2-33</td></tr></table>"
+ "</body>", "GBK");
NodeFilter tableFilter = new NodeClassFilter(TableTag.class);
OrFilter lastFilter = new OrFilter();
lastFilter.setPredicates(new NodeFilter[] { tableFilter });
try {
nodeList = myParser.parse(lastFilter);
for (int i = 0; i <= nodeList.size(); i++) {
if (nodeList.elementAt(i) instanceof TableTag) {
TableTag tag = (TableTag) nodeList.elementAt(i);
TableRow[] rows = tag.getRows();
for (int j = 0; j < rows.length; j++) {
TableRow tr = (TableRow) rows[j];
System.out.println(tr.getAttribute("id"));
if (tr.getAttribute("id").equalsIgnoreCase("tro1")) {
TableColumn[] td = tr.getColumns();
for (int k = 0; k < td.length; k++) {
// logger.fatal("<td>" +
// td[k].toPlainTextString());
System.out.println("<td>"
+ td[k].toPlainTextString());
}
}
}
}
}
} catch (ParserException e) {
e.printStackTrace();
}
}
/**
* 得到目标数据
*
* @param url:目标url
* @throws Exception
*/
public static void getDatabyUrl(String url) throws Exception {
Parser myParser = new Parser(url);
NodeList nodeList = null;
myParser.setEncoding("gb2312");
NodeFilter tableFilter = new NodeClassFilter(TableTag.class);
OrFilter lastFilter = new OrFilter();
lastFilter.setPredicates(new NodeFilter[] { tableFilter });
try {
nodeList = myParser.parse(lastFilter);
// 可以从数据table的size:19-21开始到结束
for (int i = 15; i <= nodeList.size(); i++) {
if (nodeList.elementAt(i) instanceof TableTag) {
TableTag tag = (TableTag) nodeList.elementAt(i);
TableRow[] rows = tag.getRows();
for (int j = 0; j < rows.length; j++) {
TableRow tr = (TableRow) rows[j];
if (tr.getAttribute("id") != null
&& tr.getAttribute("id").equalsIgnoreCase(
"tr02")) {
TableColumn[] td = tr.getColumns();
// 对不起,没有你要查询的记录!
if (td.length == 1) {
System.out.println("对不起,没有你要查询的记录");
} else {
for (int k = 0; k < td.length; k++) {
System.out.println("<td>内容:"
+ td[k].toPlainTextString().trim());
}
}
}
}
}
}
} catch (ParserException e) {
e.printStackTrace();
}
}
/**
* 测试已经得出有数据时table:22个,没有数据时table:19个
*
* @param args
*/
public static void main(String[] args) {
try {
// getDatabyUrl("http://gd.12530.com/user/querytonebytype.do?field=tonecode&condition=619505000000008942&type=1006&pkValue=619505000000008942");
getDatabyUrl("http://gd.12530.com/user/querytonebytype.do?field=tonecode&condition=619272000000001712&type=1006&pkValue=619272000000001712");
} catch (Exception e) {
e.printStackTrace();
}
}
}
6.html解析常用
package com.jscud.test;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStreamReader;
import org.htmlparser.Node;
import org.htmlparser.NodeFilter;
import org.htmlparser.Parser;
import org.htmlparser.filters.NodeClassFilter;
import org.htmlparser.filters.OrFilter;
import org.htmlparser.nodes.TextNode;
import org.htmlparser.tags.LinkTag;
import org.htmlparser.util.NodeList;
import org.htmlparser.util.ParserException;
import org.htmlparser.visitors.HtmlPage;
import org.htmlparser.visitors.TextExtractingVisitor;
import com.jscud.util.LogMan; //一个日志记录类
/**
* 演示了Html Parse的应用.
*
* @author scud http://www.jscud.com (http://www.jscud.com/)
*/
public class ParseHtmlTest
{
public static void main(String[] args) throws Exception
{
String aFile = "e:/jscud/temp/test.htm";
String content = readTextFile(aFile, "GBK");
test1(content);
System.out.println("====================================");
test2(content);
System.out.println("====================================");
test3(content);
System.out.println("====================================");
test4(content);
System.out.println("====================================");
test5(aFile);
System.out.println("====================================");
//访问外部资源,相对慢
test5("http://www.jscud.com (http://www.jscud.com/)");
System.out.println("====================================");
}
/**
* 读取文件的方式来分析内容.
* filePath也可以是一个Url.
*
* @param resource 文件/Url
*/
public static void test5(String resource) throws Exception
{
Parser myParser = new Parser(resource);
//设置编码
myParser.setEncoding("GBK");
HtmlPage visitor = new HtmlPage(myParser);
myParser.visitAllNodesWith(visitor);
String textInPage = visitor.getTitle();
System.out.println(textInPage);
}
/**
* 按页面方式处理.对一个标准的Html页面,推荐使用此种方式.
*/
public static void test4(String content) throws Exception
{
Parser myParser;
myParser = Parser.createParser(content, "GBK");
HtmlPage visitor = new HtmlPage(myParser);
myParser.visitAllNodesWith(visitor);
String textInPage = visitor.getTitle();
System.out.println(textInPage);
}
/**
* 利用Visitor模式解析html页面.
*
* 小优点:翻译了<>等符号
* 缺点:好多空格,无法提取link
*
*/
public static void test3(String content) throws Exception
{
Parser myParser;
myParser = Parser.createParser(content, "GBK");
TextExtractingVisitor visitor = new TextExtractingVisitor();
myParser.visitAllNodesWith(visitor);
String textInPage = visitor.getExtractedText();
System.out.println(textInPage);
}
/**
* 得到普通文本和链接的内容.
*
* 使用了过滤条件.
*/
public static void test2(String content) throws ParserException
{
Parser myParser;
NodeList nodeList = null;
myParser = Parser.createParser(content, "GBK");
NodeFilter textFilter = new NodeClassFilter(TextNode.class);
NodeFilter linkFilter = new NodeClassFilter(LinkTag.class);
//暂时不处理 meta
//NodeFilter metaFilter = new NodeClassFilter(MetaTag.class);
OrFilter lastFilter = new OrFilter();
lastFilter.setPredicates(new NodeFilter[] { textFilter, linkFilter });
nodeList = myParser.parse(lastFilter);
Node[] nodes = nodeList.toNodeArray();
for (int i = 0; i < nodes.length; i++)
{
Node anode = (Node) nodes[i];
String line = "";
if (anode instanceof TextNode)
{
TextNode textnode = (TextNode) anode;
//line = textnode.toPlainTextString().trim();
line = textnode.getText();
}
else if (anode instanceof LinkTag)
{
LinkTag linknode = (LinkTag) anode;
line = linknode.getLink();
//@todo ("") 过滤jsp标签:可以自己实现这个函数
//line = StringFunc.replace(line, "<%.*%>", "");
}
if (isTrimEmpty(line))
continue;
System.out.println(line);
}
}
/**
* 解析普通文本节点.
*
* @param content
* @throws ParserException
*/
public static void test1(String content) throws ParserException
{
Parser myParser;
Node[] nodes = null;
myParser = Parser.createParser(content, null);
nodes = myParser.extractAllNodesThatAre(TextNode.class); //exception could be
thrown here
for (int i = 0; i < nodes.length; i++)
{
TextNode textnode = (TextNode) nodes[i];
String line = textnode.toPlainTextString().trim();
if (line.equals(""))
continue;
System.out.println(line);
}
}
/**
* 读取一个文件到字符串里.
*
* @param sFileName 文件名
* @param sEncode String
* @return 文件内容
*/
public static String readTextFile(String sFileName, String sEncode)
{
StringBuffer sbStr = new StringBuffer();
try
{
File ff = new File(sFileName);
InputStreamReader read = new InputStreamReader(new FileInputStream(ff),
sEncode);
BufferedReader ins = new BufferedReader(read);
String dataLine = "";
while (null != (dataLine = ins.readLine()))
{
sbStr.append(dataLine);
sbStr.append("\r\n");
}
ins.close();
}
catch (Exception e)
{
LogMan.error("read Text File Error", e);
}
return sbStr.toString();
}
/**
* 去掉左右空格后字符串是否为空
* @param astr String
* @return boolean
*/
public static boolean isTrimEmpty(String astr)
{
if ((null == astr) || (astr.length() == 0))
{
return true;
}
if (isBlank(astr.trim()))
{
return true;
}
return false;
}
/**
* 字符串是否为空:null或者长度为0.
* @param astr 源字符串.
* @return boolean
*/
public static boolean isBlank(String astr)
{
if ((null == astr) || (astr.length() == 0))
{
return true;
}
else
{
return false;
}
}
}
三、使用 HttpClient 和 HtmlParser 实现简易爬虫
这篇文章介绍了 HtmlParser 开源包和 HttpClient 开源包的使用,在此基础上实现了一个简易的网络爬虫 (Crawler),来说明如何使用 HtmlParser 根据需要处理 Internet 上的网页,以及如何使用 HttpClient 来简化 Get 和 Post 请求操作,构建强大的网络应用程序。
本小结简单的介绍一下 HttpClinet 和 HtmlParser 两个开源的项目,以及他们的网站和提供下载的地址。
HttpClient 简介
HTTP 协议是现在的因特网最重要的协议之一。除了 WEB 浏览器之外, WEB 服务,基于网络的应用程序以及日益增长的网络计算不断扩展着 HTTP 协议的角色,使得越来越多的应用程序需要 HTTP 协议的支持。虽然 JAVA 类库 .net 包提供了基本功能,来使用 HTTP 协议访问网络资源,但是其灵活性和功能远不能满足很多应用程序的需要。而 Jakarta Commons HttpClient 组件寻求提供更为灵活,更加高效的 HTTP 协议支持,简化基于 HTTP 协议的应用程序的创建。 HttpClient 提供了很多的特性,支持最新的 HTTP 标准,可以访问这里了解更多关于 HttpClinet 的详细信息。目前有很多的开源项目都用到了 HttpClient 提供的 HTTP功能,登陆网址可 以查看这些项目。本文中使用 HttpClinet 提供的类库来访问和下载 Internet上面的网页,在后续部分会详细介绍到其提供的两种请求网络资源的方法: Get 请求和 Post 请求。Apatche 提供免费的 HTTPClien t源码和 JAR 包下载,可以登陆这里 下载最新的HttpClient 组件。笔者使用的是 HttpClient3.1。
HtmlParser 简介
当今的 Internet 上面有数亿记的网页,越来越多应用程序将这些网页作为分析和处理的数据对象。这些网页多为半结构化的文本,有着大量的标签和嵌套的结构。当我们自己开发一 些处理网页的应用程序时,会想到要开发一个单独的网页解析器,这一部分的工作必定需要付出相当的精力和时间。事实上,做为 JAVA 应用程序开发者, HtmlParser 为其提供了强大而灵活易用的开源类库,大大节省了写一个网页解析器的开销。 HtmlParser 是 http://sourceforge.net 上活跃的一个开源项目,它提供了线性和嵌套两种方式来解析网页,主要用于 html 网页的转换(Transformation) 以及网页内容的抽取 (Extraction)。HtmlParser 有如下一些易于使用的特性:过滤器 (Filters),访问者模式 (Visitors),处理自定义标签以及易于使用的 JavaBeans。正如 HtmlParser 首页所说:它是一个快速,健壮以及严格测试过的组件;以它设计的简洁,程序运行的速度以及处理 Internet 上真实网页的能力吸引着越来越多的开发者。 本文中就是利用HtmlParser 里提取网页里的链接,实现简易爬虫里的关键部分。HtmlParser 最新的版本是HtmlParser1.6,可以登陆这里下载其源码、 API 参考文档以及 JAR 包。
开发环境的搭建
笔者所使用的开发环境是 Eclipse Europa,此开发工具可以在 www.eclipse.org 免费的下载;JDK是1.6,你也可以在 www.java.sun.com 站点下载,并且在操作系统中配置好环境变量。在 Eclipse 中创建一个 JAVA 工程,在工程的 Build Path 中导入下载的Commons-httpClient3.1.Jar,htmllexer.jar 以及 htmlparser.jar 文件。
图 1. 开发环境搭建
HttpClient 基本类库使用
HttpClinet 提供了几个类来支持 HTTP 访问。下面我们通过一些示例代码来熟悉和说明这些类的功能和使用。 HttpClient 提供的 HTTP 的访问主要是通过 GetMethod 类和 PostMethod 类来实现的,他们分别对应了 HTTP Get 请求与 Http Post 请求。
GetMethod
使用 GetMethod 来访问一个 URL 对应的网页,需要如下一些步骤。
- 生成一个 HttpClinet 对象并设置相应的参数。
- 生成一个 GetMethod 对象并设置响应的参数。
- 用 HttpClinet 生成的对象来执行 GetMethod 生成的 Get 方法。
- 处理响应状态码。
- 若响应正常,处理 HTTP 响应内容。
- 释放连接。
清单 1 的代码展示了这些步骤,其中的注释对代码进行了较详细的说明。
清单 1.
/* 1 生成
HttpClinet 对象并设置参数*/
HttpClient
httpClient=new HttpClient();
//设置 Http 连接超时为5秒
httpClient.getHttpConnectionManager().getParams().setConnectionTimeout(5000);
/*2 生成 GetMethod 对象并设置参数*/
GetMethod
getMethod=new GetMethod(url);
//设置 get 请求超时为 5 秒
getMethod.getParams().setParameter(HttpMethodParams.SO_TIMEOUT,5000);
//设置请求重试处理,用的是默认的重试处理:请求三次
getMethod.getParams().setParameter(HttpMethodParams.RETRY_HANDLER, new DefaultHttpMethodRetryHandler());
/*3 执行 HTTP GET 请求*/
try{
int statusCode = httpClient.executeMethod(getMethod);
/*4 判断访问的状态码*/
if (statusCode != HttpStatus.SC_OK) {
System.err.println("Method failed: "+ getMethod.getStatusLine());
}
/*5 处理 HTTP 响应内容*/
//HTTP响应头部信息,这里简单打印
Header[]
headers=getMethod.getResponseHeaders();
for(Header h: headers)
System.out.println(h.getName()+" "+h.getValue());
//读取 HTTP 响应内容,这里简单打印网页内容
byte[] responseBody = getMethod.getResponseBody();//读取为字节数组
System.out.println(new String(responseBody));
//读取为 InputStream,在网页内容数据量大时候推荐使用
InputStream
response = getMethod.getResponseBodyAsStream();//
} catch (HttpException
e)
{
// 发生致命的异常,可能是协议不对或者返回的内容有问题
System.out.println("Please check your provided http address!");
e.printStackTrace();
}catch (IOException e)
{
// 发生网络异常
e.printStackTrace();
} finally {
/*6 .释放连接*/
getMethod.releaseConnection();
}
这里值得注意的几个地方是:
- 设置连接超时和请求超时,这两个超时的意义不同,需要分别设置。
- 响应状态码的处理。
- 返回的结果可以为字节数组,也可以为 InputStream,而后者在网页内容数据量较大的时候推荐使用。
在处理返回结果的时候可以根据自己的需要,进行相应的处理。如笔者是需要保存网页
到本地,因此就可以写一个 saveToLocaleFile(byte[] data, String filePath) 的方法,将字节数组保存成本地文件。后续的简易爬虫部分会有相应的介绍。
PostMethod
PostMethod 方法与 GetMethod 方法的使用步骤大体相同。但是由于 PostMethod 使用的是HTTP 的 Post 请求,因而请求参数的设置与 GetMethod 有所不同。在 GetMethod 中,请求的参数直接写在 URL 里,一般以这样形式出现:http://hostname:port//file?name1=value1&name2=value …。请求参数是 name,value 对。比如我想得到百度搜索“Thinking In Java”的结果网页,就可以使 GetMethod 的构造方法中的 url 为:http://www.baidu.com/s?wd=Thinking+In+Java 。而 PostMethod 则可以模拟网页里表单提交的过程,通过设置表单里 post 请求参数的值,来动态的获得返回的网页结果。清单 2 中的代码展示了如何创建一个 Post 对象,并设置相应的请求参数。
清单2
PostMethod postMethod = new PostMethod("http://dict.cn/");
postMethod.setRequestBody(new NameValuePair[]{new NameValuePair("q","java")});
HtmlParser 基本类库使用
HtmlParser 提供了强大的类库来处理 Internet 上的网页,可以实现对网页特定内容的提取和修改。下面通过几个例子来介绍 HtmlParser 的一些使用。这些例子其中的代码,有部分用在了后面介绍的简易爬虫中。以下所有的代码和方法都在在类 HtmlParser.Test.java 里,这是笔者编写的一个用来测试 HtmlParser 用法的类。
- 迭代遍历网页所有节点
网页是一个半结构化的嵌套文本文件,有类似 XML 文件的树形嵌套结构。使用HtmlParser 可以让我们轻易的迭代遍历网页的所有节点。清单 3 展示了如何来实现这个功能。
清单 3
// 循环访问所有节点,输出包含关键字的值节点
public static void extractKeyWordText(String url, String
keyword) {
try {
//生成一个解析器对象,用网页的 url 作为参数
Parser
parser = new Parser(url);
//设置网页的编码,这里只是请求了一个 gb2312 编码网页
parser.setEncoding("gb2312");
//迭代所有节点, null 表示不使用 NodeFilter
NodeList
list = parser.parse(null);
//从初始的节点列表跌倒所有的节点
processNodeList(list,
keyword);
} catch (ParserException
e) {
e.printStackTrace();
}
}
private static void processNodeList(NodeList list, String
keyword) {
//迭代开始
SimpleNodeIterator
iterator = list.elements();
while
(iterator.hasMoreNodes()) {
Node
node = iterator.nextNode();
//得到该节点的子节点列表
NodeList
childList = node.getChildren();
//孩子节点为空,说明是值节点
if (null == childList)
{
//得到值节点的值
String
result = node.toPlainTextString();
//若包含关键字,则简单打印出来文本
if
(result.indexOf(keyword) != -1)
System.out.println(result);
}
//end if
//孩子节点不为空,继续迭代该孩子节点
else
{
processNodeList(childList,
keyword);
}//end else
}//end wile
}
上面的中有两个方法:
- private static void processNodeList(NodeList list, String keyword)
该方法是用类似深度优先的方法来迭代遍历整个网页节点,将那些包含了某个关键字的值节点的值打印出来。
- public static void extractKeyWordText(String url, String keyword)
该方法生成针对 String 类型的 url 变量代表的某个特定网页的解析器,调用 1中的方法实现简单的遍历。
清单 3 的代码展示了如何迭代所有的网页,更多的工作可以在此基础上展开。比如找到某个特定的网页内部节点,其实就可以在遍历所有的节点基础上来判断,看被迭代的节点是否满足特定的需要。
- 使用 NodeFilter
NodeFilter 是一个接口,任何一个自定义的 Filter 都需要实现这个接口中的 boolean accept() 方法。如果希望迭代网页节点的时候保留当前节点,则在节点条件满足的情况下返回 true;否则返回 false。HtmlParse 里提供了很多实现了 NodeFilter 接口的类,下面就一些笔者所用到的,以及常用的 Filter 做一些介绍:
这些 Filter 来组合不同的 Filter,形成满足两个 Filter 逻辑关系结果的 Filter。
- 判断节点的孩子,兄弟,以及父亲节点情况的 Filter 有:HasChildFilterHasParentFilter,HasSiblingFilter。
- 判断节点本身情况的 Filter 有 HasAttributeFilter:判读节点是否有特定属性;LinkStringFilter:判断节点是否是具有特定模式 (pattern) url 的节点;
TagNameFilter:判断节点是否具有特定的名字;NodeClassFilter:判读节点是否是某个 HtmlParser 定义好的 Tag 类型。在 org.htmlparser.tags 包下有对应 Html标签的各种 Tag,例如 LinkTag,ImgeTag 等。
还有其他的一些 Filter 在这里不一一列举了,可以在 org.htmlparser.filters 下找到。
清单 4 展示了如何使用上面提到过的一些 filter 来抽取网页中的 <a> 标签里的 href属性值,<img> 标签里的 src 属性值,以及 <frame> 标签里的 src 的属性值。
清单4
// 获取一个网页上所有的链接和图片链接
public static void extracLinks(String url) {
try {
Parser
parser = new Parser(url);
parser.setEncoding("gb2312");
//过滤
<frame> 标签的 filter,用来提取 frame 标签里的 src 属性所、表示的链接
NodeFilter
frameFilter = new NodeFilter() {
public boolean accept(Node
node) {
if
(node.getText().startsWith("frame
src=")) {
return true;
}
else {
return false;
}
}
};
//OrFilter 来设置过滤 <a> 标签,<img> 标签和 <frame> 标签,三个标签是 or 的关系
OrFilte rorFilter = new OrFilter(new NodeClassFilter(LinkTag.class), new
NodeClassFilter(ImageTag.class));
OrFilter linkFilter = new OrFilter(orFilter,
frameFilter);
//得到所有经过过滤的标签
NodeList list =
parser.extractAllNodesThatMatch(linkFilter);
for (int i = 0; i < list.size(); i++) {
Node
tag = list.elementAt(i);
if (tag instanceof LinkTag)//<a> 标签
{
LinkTag
link = (LinkTag) tag;
String
linkUrl = link.getLink();//url
String
text = link.getLinkText();//链接文字
System.out.println(linkUrl + "**********" + text);
}
else if (tag instanceof ImageTag)//<img> 标签
{
ImageTag
image = (ImageTag) list.elementAt(i);
System.out.print(image.getImageURL()
+ "********");//图片地址
System.out.println(image.getText());//图片文字
}
else//<frame> 标签
{
//提取 frame 里 src 属性的链接如 <frame src="test.html"/>
String
frame = tag.getText();
int start =
frame.indexOf("src=");
frame
= frame.substring(start);
int end =
frame.indexOf(" ");
if (end == -1)
end
= frame.indexOf(">");
frame
= frame.substring(5, end - 1);
System.out.println(frame);
}
}
} catch (ParserException e) {
e.printStackTrace();
}
}
简单强大的 StringBean
如果你想要网页中去掉所有的标签后剩下的文本,那就是用 StringBean 吧。以下简单的代码可以帮你解决这样的问题:
清单5
StringBean sb = new StringBean();
sb.setLinks(false);//设置结果中去点链接
sb.setURL(url);//设置你所需要滤掉网页标签的页面 url
System.out.println(sb.getStrings());//打印结果
HtmlParser 提供了强大的类库来处理网页,由于本文旨在简单的介绍,因此只是将与笔者后续爬虫部分有关的关键类库进行了示例说明。感兴趣的读者可以专门来研究一下 HtmlParser 更为强大的类库。
简易爬虫的实现
HttpClient 提供了便利的 HTTP 协议访问,使得我们可以很容易的得到某个网页的源码并保存在本地;HtmlParser 提供了如此简便灵巧的类库,可以从网页中便捷的提取出指向其他网页的超链接。笔者结合这两个开源包,构建了一个简易的网络爬虫。
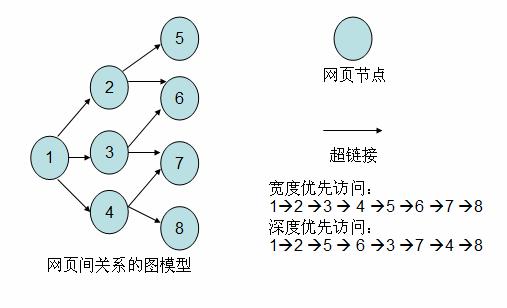
爬虫 (Crawler) 原理
学过数据结构的读者都知道有向图这种数据结构。如下图所示,如果将网页看成是图中的某一个节点,而将网页中指向其他网页的链接看成是这个节点指向其他节 点的边,那么我们很容易将整个 Internet 上的网页建模成一个有向图。理论上,通过遍历算法遍历该图,可以访问到Internet 上的几乎所有的网页。最简单的遍历就是宽度优先以及深度优先。以下笔者实现的简易爬虫就是使用了宽度优先的爬行策略。
图 2. 网页关系的建模图
简易爬虫实现流程
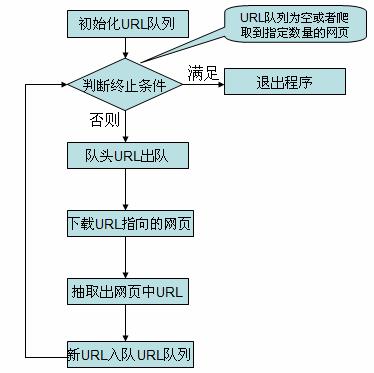
在看简易爬虫的实现代码之前,先介绍一下简易爬虫爬取网页的流程。
图 3. 爬虫流程图
各个类的源码以及说明
对应上面的流程图,简易爬虫由下面几个类组成,各个类职责如下:
Crawler.java:爬虫的主方法入口所在的类,实现爬取的主要流程。
LinkDb.java:用来保存已经访问的 url 和待爬取的 url 的类,提供url出对入队操作。
Queue.java: 实现了一个简单的队列,在 LinkDb.java 中使用了此类。
FileDownloader.java:用来下载 url 所指向的网页。
HtmlParserTool.java: 用来抽取出网页中的链接。
LinkFilter.java:一个接口,实现其 accept() 方法用来对抽取的链接进行过滤。
下面是各个类的源码,代码中的注释有比较详细的说明。
清单6 Crawler.java
package com.ie;
import java.util.Set;
public class Crawler {
/* 使用种子 url 初始化 URL 队列*/
private void initCrawlerWithSeeds(String[] seeds)
{
for(int
i=0;i<seeds.length;i++)
LinkDB.addUnvisitedUrl(seeds[i]);
}
/* 爬取方法*/
public void crawling(String[] seeds)
{
LinkFilter
filter = new LinkFilter(){
//提取以 http://www.twt.edu.cn 开头的链接
public boolean accept(String url)
{
if(url.startsWith("http://www.twt.edu.cn"))
return true;
else
return false;
}
};
//初始化 URL 队列
initCrawlerWithSeeds(seeds);
//循环条件:待抓取的链接不空且抓取的网页不多于 1000
while(!LinkDB.unVisitedUrlsEmpty()&&LinkDB.getVisitedUrlNum()<=1000)
{
//队头 URL 出对
String
visitUrl=LinkDB.unVisitedUrlDeQueue();
if(visitUrl==null)
continue;
FileDownLoader
downLoader=new FileDownLoader();
//下载网页
downLoader.downloadFile(visitUrl);
//该 url 放入到已访问的 URL 中
LinkDB.addVisitedUrl(visitUrl);
//提取出下载网页中的 URL
Set<String>
links=HtmlParserTool.extracLinks(visitUrl,filter);
//新的未访问的 URL 入队
for(String link:links)
{
LinkDB.addUnvisitedUrl(link);
}
}
}
//main 方法入口
public static void main(String[]args)
{
Crawler
crawler = new Crawler();
crawler.crawling(new String[]{"http://www.twt.edu.cn"});
}
}
清单7 LinkDb.java
package com.ie;
import java.util.HashSet;
import java.util.Set;
/**
* 用来保存已经访问过 Url 和待访问的 Url 的类
*/
public class LinkDB {
//已访问的 url 集合
private static Set<String> visitedUrl =
new HashSet<String>();
//待访问的 url 集合
private static Queue<String>
unVisitedUrl = new Queue<String>();
public static Queue<String>
getUnVisitedUrl() {
return unVisitedUrl;
}
public static void addVisitedUrl(String url) {
visitedUrl.add(url);
}
public static void removeVisitedUrl(String url) {
visitedUrl.remove(url);
}
public static String unVisitedUrlDeQueue() {
return unVisitedUrl.deQueue();
}
// 保证每个 url 只被访问一次
public static void addUnvisitedUrl(String url) {
if (url != null &&
!url.trim().equals("")
&& !visitedUrl.contains(url)
&&
!unVisitedUrl.contians(url))
unVisitedUrl.enQueue(url);
}
public static int getVisitedUrlNum() {
return visitedUrl.size();
}
public static boolean unVisitedUrlsEmpty() {
return unVisitedUrl.empty();
}
}
清单8 Queue.java
package com.ie;
import java.util.LinkedList;
/**
* 数据结构队列
*/
public class Queue<T> {
private LinkedList<T> queue=new
LinkedList<T>();
public void enQueue(T t)
{
queue.addLast(t);
}
public T deQueue()
{
return
queue.removeFirst();
}
public boolean isQueueEmpty()
{
return queue.isEmpty();
}
public boolean contians(T t)
{
return queue.contains(t);
}
public boolean empty()
{
return queue.isEmpty();
}
}
清单 9 FileDownLoader.java
package com.ie;
import java.io.DataOutputStream;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import org.apache.commons.httpclient.DefaultHttpMethodRetryHandler;
import org.apache.commons.httpclient.HttpClient;
import org.apache.commons.httpclient.HttpException;
import org.apache.commons.httpclient.HttpStatus;
import org.apache.commons.httpclient.methods.GetMethod;
import org.apache.commons.httpclient.params.HttpMethodParams;
public class FileDownLoader {
/**根据 url 和网页类型生成需要保存的网页的文件名
*去除掉 url 中非文件名字符
*/
public String getFileNameByUrl(String
url,String contentType)
{
url=url.substring(7);//remove http://
if(contentType.indexOf("html")!=-1)//text/html
{
url=
url.replaceAll("[\\?/:*|<>\"]", "_")+".html";
return url;
}
else{
return url.replaceAll("[\\?/:*|<>\"]", "_")+"."+ \
contentType.substring(contentType.lastIndexOf("/")+1);
}
}
/**保存网页字节数组到本地文件
* filePath 为要保存的文件的相对地址
*/
private void saveToLocal(byte[] data,String filePath)
{
try {
DataOutputStream
out=new DataOutputStream(new FileOutputStream(new File(filePath)));
for(int i=0;i<data.length;i++)
out.write(data[i]);
out.flush();
out.close();
} catch (IOException e) {
e.printStackTrace();
}
}
/*下载 url 指向的网页*/
public String
downloadFile(String url)
{
String filePath=null;
/* 1.生成
HttpClinet 对象并设置参数*/
HttpClient httpClient=new HttpClient();
//设置 Http 连接超时 5s
httpClient.getHttpConnectionManager().getParams().setConnectionTimeout(5000);
/*2.生成 GetMethod
对象并设置参数*/
GetMethod getMethod=new GetMethod(url);
//设置 get 请求超时 5s
getMethod.getParams().setParameter(HttpMethodParams.SO_TIMEOUT,5000);
//设置请求重试处理
getMethod.getParams().setParameter(HttpMethodParams.RETRY_HANDLER,
new
DefaultHttpMethodRetryHandler());
/*3.执行 HTTP GET 请求*/
try{
int statusCode =
httpClient.executeMethod(getMethod);
//判断访问的状态码
if (statusCode != HttpStatus.SC_OK)
{
System.err.println("Method failed: "+
getMethod.getStatusLine());
filePath=null;
}
/*4.处理 HTTP 响应内容*/
byte[] responseBody =
getMethod.getResponseBody();//读取为字节数组
//根据网页 url 生成保存时的文件名
filePath="temp\\"+getFileNameByUrl(url,getMethod.getResponseHeader("Content-Type").getValue());
saveToLocal(responseBody,filePath);
} catch (HttpException e) {
// 发生致命的异常,可能是协议不对或者返回的内容有问题
System.out.println("Please check your provided http address!");
e.printStackTrace();
} catch (IOException e) {
// 发生网络异常
e.printStackTrace();
} finally {
// 释放连接
getMethod.releaseConnection();
}
return filePath;
}
//测试的 main 方法
public static void main(String[]args)
{
FileDownLoader
downLoader = new FileDownLoader();
downLoader.downloadFile("http://www.twt.edu.cn");
}
}
清单 10 HtmlParserTool.java
package com.ie;
import java.util.HashSet;
import java.util.Set;
import org.htmlparser.Node;
import org.htmlparser.NodeFilter;
import org.htmlparser.Parser;
import
org.htmlparser.filters.NodeClassFilter;
import org.htmlparser.filters.OrFilter;
import org.htmlparser.tags.LinkTag;
import org.htmlparser.util.NodeList;
import org.htmlparser.util.ParserException;
public class HtmlParserTool {
//
获取一个网站上的链接,filter 用来过滤链接
public
static Set<String> extracLinks(String url,LinkFilter filter) {
Set<String>
links = new HashSet<String>();
try
{
Parser
parser = new Parser(url);
parser.setEncoding("gb2312");
//
过滤 <frame
>标签的 filter,用来提取 frame 标签里的 src 属性所表示的链接
NodeFilter
frameFilter = new NodeFilter() {
public
boolean accept(Node node) {
if
(node.getText().startsWith("frame src=")) {
return
true;
}
else {
return
false;
}
}
};
//
OrFilter 来设置过滤 <a> 标签,和
<frame> 标签
OrFilter
linkFilter = new OrFilter(new NodeClassFilter(
LinkTag.class),
frameFilter);
//
得到所有经过过滤的标签
NodeList
list = parser.extractAllNodesThatMatch(linkFilter);
for
(int i = 0; i < list.size(); i++) {
Node
tag = list.elementAt(i);
if
(tag instanceof LinkTag)// <a> 标签
{
LinkTag
link = (LinkTag) tag;
String
linkUrl = link.getLink();// url
if(filter.accept(linkUrl))
links.add(linkUrl);
}
else// <frame> 标签
{
// 提取 frame 里 src 属性的链接如 <frame src="test.html"/>
String
frame = tag.getText();
int
start = frame.indexOf("src=");
frame
= frame.substring(start);
int
end = frame.indexOf(" ");
if
(end == -1)
end
= frame.indexOf(">");
String
frameUrl = frame.substring(5, end - 1);
if(filter.accept(frameUrl))
links.add(frameUrl);
}
}
}
catch (ParserException e) {
e.printStackTrace();
}
return
links;
}
//测试的 main 方法
public
static void main(String[]args)
{
Set<String> links =
HtmlParserTool.extracLinks(
"http://www.twt.edu.cn",new
LinkFilter()
{
//提取以 http://www.twt.edu.cn
开头的链接
public
boolean accept(String url) {
if(url.startsWith("http://www.twt.edu.cn"))
return
true;
else
return
false;
}
});
for(String
link : links)
System.out.println(link);
}
}
清单11 LinkFilter.java
package com.ie;
public interface LinkFilter {
public boolean accept(String url);
}
这些代码中关键的部分都在 HttpClient 和 HtmlParser 介绍中说明过了,其他部分也比较容易,请感兴趣的读者自行理解。
Htmlparser汇总说明
关键字: htmlparser
需要做一个垂直搜索引擎,比较了nekohtml和htmlparser 的功能,尽管nekohtml在容错性、性能等方面的口碑好像比htmlparser好(htmlunit也用的是nekohtml),但感觉 nekohtml的测试用例和文档都比htmlparser都少,而且htmlparser基本上能够满足垂直搜索引擎页面处理分析的需求,因此先研究一
下htmlparser的使用,有空再研究nekohtml和mozilla html parser的使用。
html的功能还是官方说得最为清楚,
引用
HTML Parser is a Java
library used to parse HTML in either a linear or nested fashion. Primarily used
for transformation or extraction, it features filters, visitors, custom tags
and easy to use JavaBeans. It is a fast, robust and well tested package.
The two fundamental use-cases that are handled by the parser
are extraction and transformation (the syntheses use-case, where HTML pages are
created from scratch, is better handled by other tools closer to the source of
data). While prior versions concentrated on data extraction from web pages,
Version 1.4 of the HTMLParser has substantial improvements in the area of
transforming web pages, with simplified tag creation and editing, and verbatim
toHtml() method output.
研究的重点还是extraction的使用,有空再研究transformation的使用。
1、htmlparser对html页面处理的数据结构
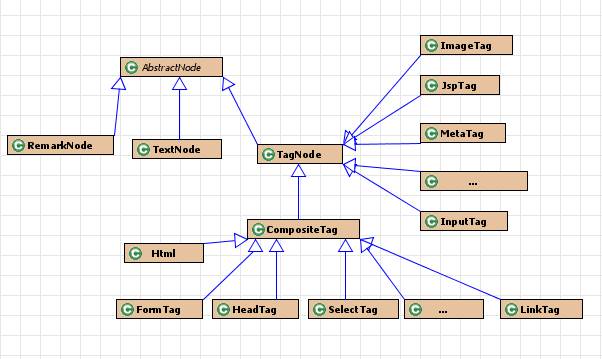
如图所示,HtmlParser采用了经典的Composite模式,通过RemarkNode、TextNode、TagNode、AbstractNode和Tag来描述HTML页面各元素。
* org.htmlparser.Node:
Node接口定义了进行树形结构节点操作的各种典型操作方法,
包括:
节点到html文本、text文本的方法:toPlainTextString、toHtml
典型树形结构遍历的方法:getParent、getChildren、getFirstChild、getLastChild、getPreviousSibling、getNextSibling、getText
获取节点对应的树形结构结构的顶级节点Page对象方法:getPage
获取节点起始位置的方法:getStartPosition、getEndPosition
Visitor方法遍历节点时候方法:accept (NodeVisitor visitor)
Filter方法:collectInto (NodeList list, NodeFilter filter)
Object方法:toString、clone
* org.htmlparser.nodes.AbstractNode:
AbstractNode是形成HTML树形结构抽象基类,实现了Node接口。
在htmlparser中,Node分成三类:
RemarkNode:代表Html中的注释
TagNode:标签节点。
TextNode:文本节点
这三类节点都继承AbstractNode。
* org.htmlparser.nodes.TagNode:
TagNode包含了对HTML处理的核心的各个类,是所有TAG的基类,其中有分为包含其他TAG的复合节点ComositeTag和不包含其他TAG的叶子节点Tag。
复合节点CompositeTag:
AppletTag,BodyTag,Bullet,BulletList,DefinitionList,DefinitionListBullet,Div,FormTag,FrameSetTag,HeadingTag,
HeadTag,Html,LabelTag,LinkTag,ObjectTag,ParagraphTag,ScriptTag,SelectTag,Span,StyleTag,TableColumn,
TableHeader,TableRow,TableTag,TextareaTag,TitleTag
叶子节点TAG:
BaseHrefTag,DoctypeTag,FrameTag,ImageTag,InputTag,JspTag,MetaTag,ProcessingInstructionTag,
2、htmlparser对html页面处理的算法
主要是如下几种方式
l 采用Visitor方式访问Html
3、htmlparser关键包结构说明
htmlparser其实核心代码并不多,好好研究一下其代码,弥补文档不足的问题。同时htmlparser的代码注释和单元测试用例还是很齐全的,也有助于了解htmlparser的用法。
3.1、org.htmlparser
定义了htmlparser的一些基础类。其中最为重要的是Parser类。
Parser 是htmlparser的最核心的类,其构造函数提供了如下:Parser.createParser (String html, String charset)、
Parser ()、Parser (Lexer lexer, ParserFeedback fb)、
Parser (URLConnection connection, ParserFeedback fb)、Parser (String resource, ParserFeedback
feedback)、 Parser (String resource)
各构造函数的具体用法及含义可以查看其代码,很容易理解。
Parser常用的几个方法:
* elements获取元素
Parser parser = new Parser (”http://www.google.com”);
for
(NodeIterator i = parser.elements (); i.hasMoreElements (); )
processMyNodes (i.nextNode ());
* parse (NodeFilter filter):通过NodeFilter方式获取
* visitAllNodesWith (NodeVisitor visitor):通过Nodevisitor方式
* extractAllNodesThatMatch (NodeFilter filter):通过NodeFilter方式
3.2、org.htmlparser.beans
对Visitor和Filter的方法进行了封装,定义了针对一些常用html元素操作的bean,简化对常用元素的提取操作。
包括:FilterBean、HTMLLinkBean、HTMLTextBean、LinkBean、StringBean、BeanyBaby等。
3.3、org.htmlparser.nodes
定义了基础的node,包括:AbstractNode、RemarkNode、TagNode、TextNode等。
3.4、org.htmlparser.tags
定义了htmlparser的各种tag。
3.5、org.htmlparser.filters
定义了htmlparser所提供的各种filter,主要通过extractAllNodesThatMatch (NodeFilter filter)来对html页面指定类型的元素进行过滤,包括:AndFilter、 CssSelectorNodeFilter、
HasAttributeFilter、HasChildFilter、 HasParentFilter、HasSiblingFilter、
IsEqualFilter、LinkRegexFilter、 LinkStringFilter、NodeClassFilter、
NotFilter、OrFilter、RegexFilter、 StringFilter、TagNameFilter、XorFilter
3.6、org.htmlparser.visitors
定义了htmlparser所提供的各种visitor,主要通过visitAllNodesWith
(NodeVisitor visitor)来对 html页面元素进行遍历,包括:HtmlPage、LinkFindingVisitor、NodeVisitor、 ObjectFindingVisitor、StringFindingVisitor、TagFindingVisitor、 TextExtractingVisitor、UrlModifyingVisitor
3.7、org.htmlparser.parserapplications
定义了一些实用的工具,包括LinkExtractor、SiteCapturer、StringExtractor、WikiCapturer,这几个类也可以作为htmlparser使用样例。
3.8、org.htmlparser.tests
对各种功能的单元测试用例,也可以作为htmlparser使用的样例。
4、htmlparser的使用样例
57. import java.net.URL;
58.
59. import
junit.framework.TestCase;
60.
61. import org.apache.log4j.Logger;
62. import
org.htmlparser.Node;
63. import
org.htmlparser.NodeFilter;
64. import
org.htmlparser.Parser;
65. import
org.htmlparser.Tag;
66. import
org.htmlparser.beans.LinkBean;
67. import
org.htmlparser.filters.NodeClassFilter;
68. import
org.htmlparser.filters.OrFilter;
69. import
org.htmlparser.filters.TagNameFilter;
70. import
org.htmlparser.tags.HeadTag;
71. import
org.htmlparser.tags.ImageTag;
72. import
org.htmlparser.tags.InputTag;
73. import
org.htmlparser.tags.LinkTag;
74. import
org.htmlparser.tags.OptionTag;
75. import
org.htmlparser.tags.SelectTag;
76. import
org.htmlparser.tags.TableColumn;
77. import
org.htmlparser.tags.TableRow;
78. import
org.htmlparser.tags.TableTag;
79. import org.htmlparser.tags.TitleTag;
80. import
org.htmlparser.util.NodeIterator;
81. import
org.htmlparser.util.NodeList;
82. import
org.htmlparser.util.ParserException;
83. import
org.htmlparser.visitors.HtmlPage;
84. import
org.htmlparser.visitors.NodeVisitor;
85. import
org.htmlparser.visitors.ObjectFindingVisitor;
86.
87. public class
ParserTestCase extends TestCase {
88.
89. private static final Logger
logger = Logger.getLogger(ParserTestCase.class);
90.
91. public ParserTestCase(String
name) {
92.
super(name);
93. }
94. /*
95. * 测试ObjectFindVisitor的用法
96. */
97. public void
testImageVisitor() {
98. try
{
99.
ImageTag imgLink;
100.
ObjectFindingVisitor visitor = new ObjectFindingVisitor(
101.
ImageTag.class);
102.
Parser parser = new Parser();
103.
parser.setURL(”http://www.google.com”);
104.
parser.setEncoding(parser.getEncoding());
105.
parser.visitAllNodesWith(visitor);
106.
Node[] nodes = visitor.getTags();
107.
for (int i = 0; i < nodes.length; i++) {
108.
imgLink = (ImageTag) nodes[i];
109.
logger.fatal(”testImageVisitor() ImageURL = “
110.
+ imgLink.getImageURL());
111.
logger.fatal(”testImageVisitor() ImageLocation = “
112.
+ imgLink.extractImageLocn());
113.
logger.fatal(”testImageVisitor() SRC = “
114.
+ imgLink.getAttribute(”SRC”));
115.
}
116.
}
117.
catch (Exception e) {
118.
e.printStackTrace();
119.
}
120. }
121. /*
122. * 测试TagNameFilter用法
123. */
124. public void testNodeFilter()
{
125. try
{
126.
NodeFilter filter = new TagNameFilter(”IMG”);
127.
Parser parser = new Parser();
128.
parser.setURL(”http://www.google.com”);
129.
parser.setEncoding(parser.getEncoding());
130.
NodeList list = parser.extractAllNodesThatMatch(filter);
131.
for (int i = 0; i < list.size(); i++) {
132.
logger.fatal(”testNodeFilter() ” + list.elementAt(i).toHtml());
133.
}
134. }
catch (Exception e) {
135.
e.printStackTrace();
136.
}
137.
138. }
139. /*
140. * 测试NodeClassFilter用法
141. */
142. public void testLinkTag()
{
143. try
{
144.
145.
NodeFilter filter = new NodeClassFilter(LinkTag.class);
146.
Parser parser = new Parser();
147.
parser.setURL(”http://www.google.com”);
148.
parser.setEncoding(parser.getEncoding());
149.
NodeList list = parser.extractAllNodesThatMatch(filter);
150.
for (int i = 0; i < list.size(); i++) {
151.
LinkTag node = (LinkTag) list.elementAt(i);
152.
logger.fatal(”testLinkTag()
Link is :” + node.extractLink());
153.
}
154. }
catch (Exception e) {
155.
e.printStackTrace();
156.
}
157.
158. }
159. /*
160. * 测试<link
href=” text=’text/css’ rel=’stylesheet’
/>用法
161. */
162. public void testLinkCSS()
{
163. try
{
164.
165.
Parser parser = new Parser();
166.
parser
167.
.setInputHTML(”<head><title>Link Test</title>”
168.
+ “<link href=’/test01/css.css’ text=’text/css’ rel=’stylesheet’
/>”
169.
+ “<link href=’/test02/css.css’ text=’text/css’ rel=’stylesheet’
/>”
170.
+ “</head>” + “<body>”);
171.
parser.setEncoding(parser.getEncoding());
172.
NodeList nodeList = null;
173.
174.
for (NodeIterator e = parser.elements(); e.hasMoreNodes();) {
175.
Node node = e.nextNode();
176.
logger
177.
.fatal(”testLinkCSS()” + node.getText()
178.
+ node.getClass());
179.
180.
}
181. }
catch (Exception e) {
182.
e.printStackTrace();
183.
}
184. }
185. /*
186. * 测试OrFilter的用法
187. */
188. public void testOrFilter()
{
189.
NodeFilter inputFilter = new NodeClassFilter(InputTag.class);
190.
NodeFilter selectFilter = new NodeClassFilter(SelectTag.class);
191.
Parser myParser;
192.
NodeList nodeList = null;
193.
194. try
{
195.
Parser parser = new Parser();
196.
parser
197.
.setInputHTML(”<head><title>OrFilter
Test</title>”
198.
+ “<link href=’/test01/css.css’ text=’text/css’ rel=’stylesheet’
/>”
199.
+ “<link href=’/test02/css.css’ text=’text/css’ rel=’stylesheet’
/>”
200. +
“</head>”
201.
+ “<body>”
202.
+ “<input type=’text’
value=’text1′ name=’text1′/>”
203.
+ “<input type=’text’
value=’text2′ name=’text2′/>”
204.
+ “<select><option id=’1′>1</option><option
id=’2′>2</option><option id=’3′></option></select>”
205.
+ “<a href=’http://www.yeeach.com’>yeeach.com</a>”
206.
+ “</body>”);
207.
208.
parser.setEncoding(parser.getEncoding());
209.
OrFilter lastFilter = new OrFilter();
210.
lastFilter.setPredicates(new NodeFilter[] { selectFilter,
211.
inputFilter });
212.
nodeList = parser.parse(lastFilter);
213.
for (int i = 0; i <= nodeList.size(); i++) {
214.
if (nodeList.elementAt(i) instanceof InputTag) {
215.
InputTag tag = (InputTag) nodeList.elementAt(i);
216.
logger.fatal(”OrFilter tag name is :” + tag.getTagName()
217.
+ ” ,tag value is:” + tag.getAttribute(”value”));
218.
}
219.
if (nodeList.elementAt(i) instanceof SelectTag) {
220.
SelectTag tag = (SelectTag) nodeList.elementAt(i);
221.
NodeList list = tag.getChildren();
222.
223.
for (int j = 0; j < list.size(); j++) {
224.
OptionTag
option = (OptionTag) list.elementAt(j);
225.
logger
226.
.fatal(”OrFilter Option”
227.
+ option.getOptionText());
228. }
229.
230.
}
231.
}
232.
233. }
catch (ParserException e) {
234.
e.printStackTrace();
235.
}
236. }
237. /*
238. * 测试对<table><tr><td></td></tr></table>的解析
239. */
240. public void testTable()
{
241.
Parser myParser;
242.
NodeList nodeList = null;
243.
myParser = Parser.createParser(”<body> ” + “<table
id=’table1′ >”
244.
+ “<tr><td>1-11</td><td>1-12</td><td>1-13</td>”
245.
+
“<tr><td>1-21</td><td>1-22</td><td>1-23</td>”
246.
+
“<tr><td>1-31</td><td>1-32</td><td>1-33</td></table>”
247.
+ “<table id=’table2′ >”
248.
+ “<tr><td>2-11</td><td>2-12</td><td>2-13</td>”
249.
+
“<tr><td>2-21</td><td>2-22</td><td>2-23</td>”
250.
+
“<tr><td>2-31</td><td>2-32</td><td>2-33</td></table>”
251.
+ “</body>”, “GBK”);
252.
NodeFilter tableFilter = new NodeClassFilter(TableTag.class);
253.
OrFilter lastFilter = new OrFilter();
254.
lastFilter.setPredicates(new NodeFilter[] { tableFilter });
255. try
{
256.
nodeList = myParser.parse(lastFilter);
257.
for (int i = 0; i <= nodeList.size(); i++) {
258.
if (nodeList.elementAt(i) instanceof TableTag) {
259.
TableTag tag = (TableTag) nodeList.elementAt(i);
260.
TableRow[] rows = tag.getRows();
261.
262.
for (int j = 0; j < rows.length; j++) {
263.
TableRow tr = (TableRow) rows[j];
264.
TableColumn[] td = tr.getColumns();
265.
for (int k = 0; k < td.length; k++) {
266.
logger.fatal(”<td>” + td[k].toPlainTextString());
267.
}
268.
269.
}
270.
271.
}
272.
}
273.
274. }
catch (ParserException e) {
275.
e.printStackTrace();
276.
}
277. }
278. /*
279. * 测试NodeVisitor的用法,遍历所有节点
280. */
281. public void testVisitorAll()
{
282. try
{
283. Parser parser = new
Parser();
284.
parser.setURL(”http://www.google.com”);
285.
parser.setEncoding(parser.getEncoding());
286.
NodeVisitor visitor = new NodeVisitor() {
287.
public void visitTag(Tag tag) {
288.
logger.fatal(”testVisitorAll()
Tag name is :”
289.
+ tag.getTagName() + ” \n Class is :”
290.
+ tag.getClass());
291.
}
292.
293.
};
294.
295.
parser.visitAllNodesWith(visitor);
296. }
catch (ParserException e) {
297.
e.printStackTrace();
298.
}
299. }
300. /*
301. * 测试对指定Tag的NodeVisitor的用法
302. */
303. public void testTagVisitor()
{
304. try
{
305.
306.
Parser parser = new Parser(
307.
“<head><title>dddd</title>”
308.
+ “<link href=’/test01/css.css’ text=’text/css’ rel=’stylesheet’
/>”
309.
+ “<link href=’/test02/css.css’ text=’text/css’ rel=’stylesheet’
/>”
310.
+ “</head>” + “<body>”
311.
+ “<a href=’http://www.yeeach.com’>yeeach.com</a>”
312.
+ “</body>”);
313.
NodeVisitor visitor = new NodeVisitor() {
314.
public void visitTag(Tag tag) {
315.
if (tag instanceof HeadTag) {
316.
logger.fatal(”visitTag()
HeadTag : Tag name is :”
317.
+ tag.getTagName() + ” \n Class is :”
318.
+ tag.getClass() + “\n Text is :”
319.
+ tag.getText());
320.
} else if (tag instanceof TitleTag) {
321.
logger.fatal(”visitTag() TitleTag : Tag name is :”
322.
+ tag.getTagName() + ” \n Class is :”
323.
+
tag.getClass() + “\n Text is :”
324.
+ tag.getText());
325.
326.
327.
} else if (tag instanceof LinkTag) {
328.
logger.fatal(”visitTag() LinkTag : Tag name is :”
329.
+ tag.getTagName() + ” \n Class is :”
330.
+ tag.getClass() + “\n Text is :”
331.
+ tag.getText() + ” \n getAttribute is :”
332. +
tag.getAttribute(”href”));
333.
} else {
334.
logger.fatal(”visitTag() : Tag name is :”
335.
+ tag.getTagName() + ” \n Class is :”
336. +
tag.getClass() + “\n Text is :”
337.
+ tag.getText());
338.
}
339.
340.
}
341.
342.
};
343.
344.
parser.visitAllNodesWith(visitor);
345. }
catch (Exception e) {
346.
e.printStackTrace();
347.
}
348. }
349. /*
350. * 测试HtmlPage的用法
351. */
352. public void testHtmlPage()
{
353.
String inputHTML = “<html>” + “<head>”
354.
+ “<title>Welcome to the HTMLParser website</title>”
355.
+ “</head>” + “<body>” + “Welcome to HTMLParser”
356.
+ “<table id=’table1′ >”
357.
+ “<tr><td>1-11</td><td>1-12</td><td>1-13</td>”
358.
+
“<tr><td>1-21</td><td>1-22</td><td>1-23</td>”
359.
+
“<tr><td>1-31</td><td>1-32</td><td>1-33</td></table>”
360.
+ “<table id=’table2′ >”
361.
+ “<tr><td>2-11</td><td>2-12</td><td>2-13</td>”
362.
+
“<tr><td>2-21</td><td>2-22</td><td>2-23</td>”
363.
+
“<tr><td>2-31</td><td>2-32</td><td>2-33</td></table>”
364.
+ “</body>” + “</html>”;
365. Parser
parser = new Parser();
366. try
{
367.
parser.setInputHTML(inputHTML);
368.
parser.setEncoding(parser.getURL());
369.
HtmlPage page = new HtmlPage(parser);
370.
parser.visitAllNodesWith(page);
371.
logger.fatal(”testHtmlPage -title is :” + page.getTitle());
372.
NodeList list = page.getBody();
373.
374.
for (NodeIterator iterator = list.elements(); iterator
375.
.hasMoreNodes();) {
376.
Node node = iterator.nextNode();
377.
logger.fatal(”testHtmlPage -node
is :” + node.toHtml());
378.
}
379.
380. }
catch (ParserException e) {
381.
// TODO Auto-generated catch block
382.
e.printStackTrace();
383.
}
384. }
385. /*
386. * 测试LinkBean的用法
387. */
388. public void testLinkBean()
{
389.
Parser parser = new Parser();
390.
391. LinkBean
linkBean = new LinkBean();
392.
linkBean.setURL(”http://www.google.com”);
393.
URL[] urls = linkBean.getLinks();
394.
395. for
(int i = 0; i < urls.length; i++) {
396.
URL url = urls[i];
397.
logger.fatal(”testLinkBean()
-url is :” + url);
398.
}
399.
400. }
401.
402. }